
Koncepcja Data Fabric w eksabajtowej skali zapewnia sukces dzięki
AI, analityce oraz kontenerach w chmurze hybrydowej

Przedsiębiorstwa poszukują strategii, które pozwolą im wykorzystać potencjał danych, analityki oraz sztucznej inteligencji (AI). Jednocześnie mamy do czynienia z zasadniczą zmianą w ramach strategii infrastrukturalnych dzięki chmurze hybrydowej oraz konteneryzacji Kubernetes, które są wdrażane na niespotykaną wcześniej skalę. Jest to wieloetapowy proces, w czasie którego musimy podjąć wiele ważnych decyzji. Oprogramowanie HPE Data Fabric (wcześniej znane jako platforma MapR Data Platform) pozwala na pobieranie i przechowywanie danych oraz zarządzanie nimi na szeroką skalę, aby zadbać o ich dostępność w ramach nowych technik komputerowych i narzędzi. HPE Data Fabric integruje się z platformą HPE Container Platform i umożliwia wdrożenie aplikacji opartych na danych w Kubernetes przy zachowaniu odpowiedniej skali i w dowolnej infrastrukturze – na miejscu, w wielu chmurach publicznych lub na brzegu siec
NOWA ARCHITEKTURA DATA FABRIC

WIZJA HPE DOTYCZĄCA DATA FABRIC
Potrzebne jest unikatowe i przełomowe podejście, które połączy najważniejsze nowe technologie, takie jak Hadoop, Spark, uczenie maszynowe (ML) oraz narzędzia AI, przy jednoczesnej optymalizacji pod kątem dużej skali, niezawodności i elastyczności w ramach konteneryzacji. Krytyczne znaczenie ma również elastyczność globalnego wdrożenia, uzyskiwana poprzez płynne łączenie rozwiązań wdrożonych na miejscu, na brzegu sieci lub w jednej lub większej liczbie chmur. Architektura HPE Data Fabric została opracowana, zaprojektowana i wdrożona za pomocą zestawu zasad, które pozwalają spełnić najważniejsze kryteria klientów pozwalające dokonać przemyślanego wyboru
HPE DATA FABRIC
1. Obsługa różnego rodzaju danych, od dużych do małych zbiorów, danych ustrukturyzowanych i nieustrukturyzowanych, w tabelach, strumieniach lub plikach, danych
związanych z Internetem rzeczy (IoT) oraz czujnikami – zwłaszcza każdego typu danych z dowolnego źródła danych, włączając w to stały zestaw mechanizmów pobierania
2. Wsparcie dla różnych narzędzi przetwarzania oraz struktur, takich jak Hadoop, Spark, ML, TensorFlow oraz Caffe
3. Jednoczesne uruchamianie AI oraz aplikacji analitycznych, bez wymagań dotyczących wielu klastrów lub silosów, co oznacza krótszy czas wejścia na rynek, mniej prac związanych z konserwacją oraz bardziej spójne wyniki z powodu wykorzystywania tego samego zestawu danych przez osoby zajmujące się data science oraz analityką
4. Zapewnianie szerokiej gamy otwartych API – POSIX, HDFS, S3, JSON, HBase, Kafka, REST
5. Oferowanie strumieniowania pub-sub i rozwiązania edge first w zakresie wszystkich danych w ruchu z dowolnego źródła danych, włączając w to czujniki IoT
6. Zaufanie – zabezpieczenia zostały wbudowane w rozwiązanie
7. Zapewnianie niezawodności, bezpieczeństwa i skali, które pozwalają operować w globalnym środowisku produkcyjnym AI o znaczeniu krytycznym oraz aplikacjach analitycznych
8. Ułatwianie przenoszenia danych i aplikacji pomiędzy lokalizacjami na miejscu i w chmurze poprzez wsparcie aplikacji za pomocą Kubernetes
9. Działanie w dowolnej chmurze, które stanowi bardzo ważną cechę, dzięki której klient może doświadczyć korzyści płynących z chmury i nie spotka się z blokadą przy korzystaniu z wielu chmur lub lokalnych centrów danych
10. Zapewnianie globalnej architektury Data Fabric do równoczesnego pobierania, przechowywania, kontrolowania, przetwarzania, stosowania i analizowania danych
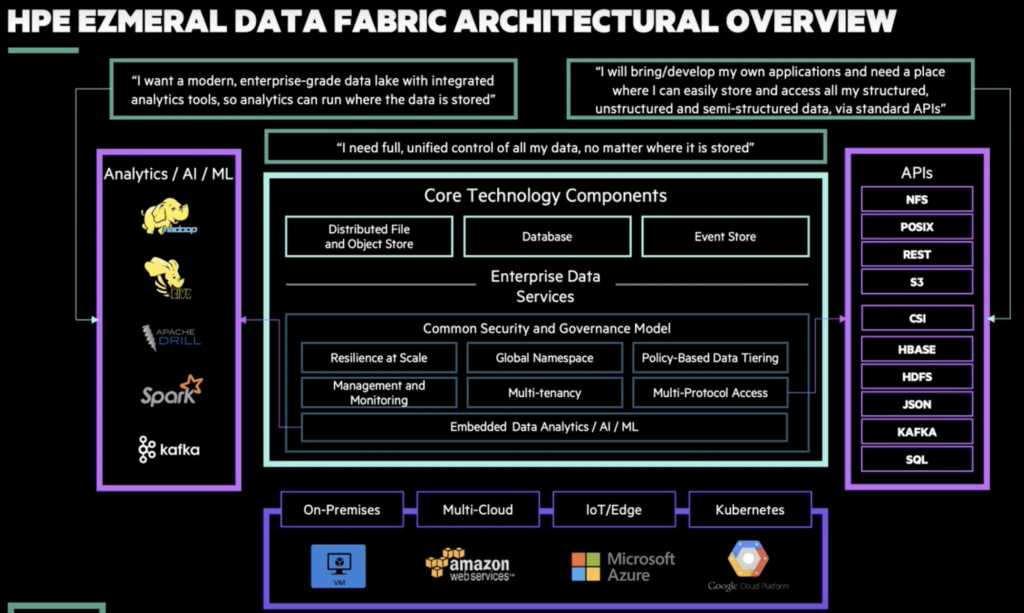
HPE Data Fabric zapewnia odpowiedź na fundamentalne wyzwania dzięki unikatowej, globalnej architekturze Data Fabric do AI i aplikacji analitycznych w skali produkcyjnej. Jest to spowodowane tym, że architektura Data Fabric zapewnia niezrównaną skalę, wydajność i niezawodność, które pozwalają zadbać o dostarczanie czystej wartości biznesowej oraz przewagi konkurencyjnej.
WIĘCEJ INFORMACJI:
hpe.com/info/data-fabric









